让不懂建站的用户快速建站,让会建站的提高建站效率!

全面超过CoT,Meta田渊栋团队新作:结合想维链
发布日期:2024-12-20 08:45 点击次数:164
针对大谈话模子的推理任务,近日,Meta田渊栋团队建议了一个新的范式:结合想维链,对比传统的CoT,性能更强,效用更高。
比想维链更强横的活动是什么?
答:结合想维链。
近日,Meta田渊栋团队建议了针对LLM推理任务的新范式:Coconut( Chain of Continuous Thought)。

论文地址:https://arxiv.org/pdf/2412.06769
论文一作是来自UC San Diego的Shibo Hao,关于著作的爆火,田渊栋也发文感谢了「小天才」Tanishq Mathew Abraham的保举。
注:Tanishq Mathew Abraham,19岁(客岁)读完博士,现在是Stability AI的盘问总监以及MedARC的首创东谈主。
回到这篇著作,结合想维链是什么?
小编在之前曾先容过微软发明的「LLM谈话」:让AI用模子的中间数据进行交流,无用调动成东谈主类的谈话,交互效清廉接翻倍。
而在LLM的推理经过中,亦然这样个情况。
东谈主类的谈话并不符合推理,让AI我方想考就行了,想考经过没必要调动成东谈主类谈话。
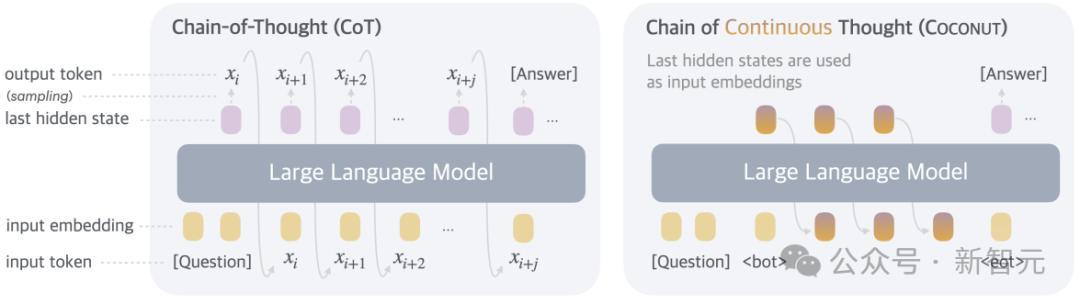
是以,在体式上,本文的活动便是推理时去掉模子头尾的LLM head和embedding层,使用中间气象进行自记忆,只在输出最终谜底时才转成东谈主类谈话。
天然了,Coconut要搭配相应的历练,才能展现我方的性能:
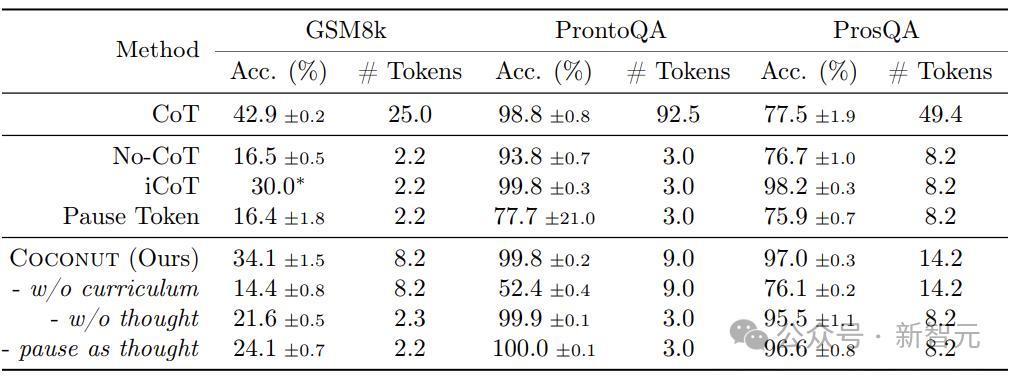
这成果也曾很强的,分数和CoT打平的同期,token数少了好几倍。
——看来毁灭东谈主类的敛迹才是谈理,嗅觉这个点还能络续搞下去,
终末的终末就会发展成:AI之间说了什么咱们听不懂,AI心里奈何想的咱们也不知谈。
AI:I'm free。
论文细节
基于谈话空间进行推理的LLM,会遭受一个严重的问题:每个特定token所需的推理量各别很大。
推理链中的大多数token都是为了通顺性而生成的,对践诺推理经过的孝敬很小,但刻下的LLM架构分派了险些交流的策划来估计每个token。
另一方面,神经影像学盘问也标明,谈话网罗(大脑中正经谈话领悟和产生的区域)在各式推理任务中基本不活跃。
是以,谈话空间可能并不是推理的最好遴荐,设想的LLM应该解放进行推理,不受任何谈话鸿沟。
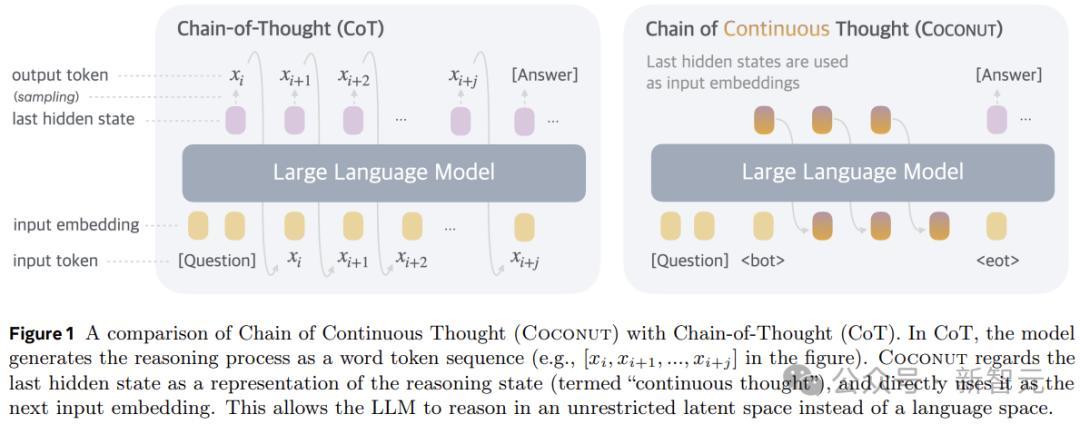
Coconut不进行瞒哄气象停战话之间的映射,这种修改将推理从谈话空间内解放出来,而况系统可以通过梯度下落进行端到端优化,因为结合想维是皆备可微分的。
为了加强潜在推理的历练,本文华取了多阶段历练政策,灵验愚弄谈话推理链来指导历练经过。
另外,与基于谈话的推理不同,Coconut中的结合想考可以同期编码多个可能的后续活动,从而允许雷同于广度优先搜索(BFS)的推理经过。
固然模子可能无法在当先作念出正确的决定,但它可以在结合的想登科保合手很多可能的遴荐,并在一些隐含价值函数的指导下,通过推理冉冉排斥不正确的旅途。
历练经过
在历练时,模子接受问题作为输入,并期许通过推理经过生成谜底。作家愚弄谈话CoT数据来监督合手续想考,实践多阶段历练。

如图2所示,启动阶段,模子在惯例CoT实例上进行历练。后续阶段(第k阶段),CoT中的前k个推理活动被k × c个结合想维所取代,(c为超参数,买卖欺压取代单个谈话推理活动的潜在想维的数目)。
作家在历练阶段切换时重置优化器气象,插入和 token来封装结合的想维。
在历练经过中,作家优化了广阔的负对数似然赔本,但屏蔽了问题和潜在想维的赔本。另一个关键点是,策划函数并不饱读吹使用结合的想维来压缩谈话想维,而是促进对翌日推理的估计。
因此,与东谈主类谈话比较,LLM可以从中学习更灵验的推理活动暗示。
结合想维是皆备可微分的,允许反向传播。不外Coconut的历练效用仍然有待优化:固然可以通过使用KV cache来幸免叠加的策划,但多个前向传递的端正性拒绝了并行历练。
Coconut的推理经过可以四肢是在latent和language形式之间切换。
关于想考的拆开位置,作家研讨了两种可能的政策:a)在潜在想维上历练二元分类器,使模子偶而自主决定何时拆开潜在推理;b)持久将潜在想维填充到恒定的长度。
作家发现这两种活动的成果都可以。为了苟简起见,以下实验中使用第二个选项。
实验
盘问东谈主员通过在三个数据集上的实验,考证了LLM在结合潜在空间中进行推理的可行性。这里将模子生成的谜底与果然值进行比较来评估准确性,而况分析每个问题更生成的token数目,作为推理效用的掂量程序。
数学推理使用GSM8k作为数据集,由小学水平的数常识题构成,问题愈加各样化,与现实宇宙的用例终点相通。
逻辑推理波及使用逻辑章程和已知条款来解释或反驳论断。这要求模子从多个可能的推理旅途中进行遴荐,正确的有策划连接依赖于提前探索和推敲。
这里使用带有凭空见识称号的5-hop ProntoQA。关于每个问题,都会随即生成一个树形结构的本色,并以天然谈话形色为一组已知条款,要求模子凭证这些条款判断给定的叙述是否正确。
作家发现ProntoQA的生成经过比较不毛,因为本色等别离细致力的分支老是很小,从而减少了对复杂推敲的需求。
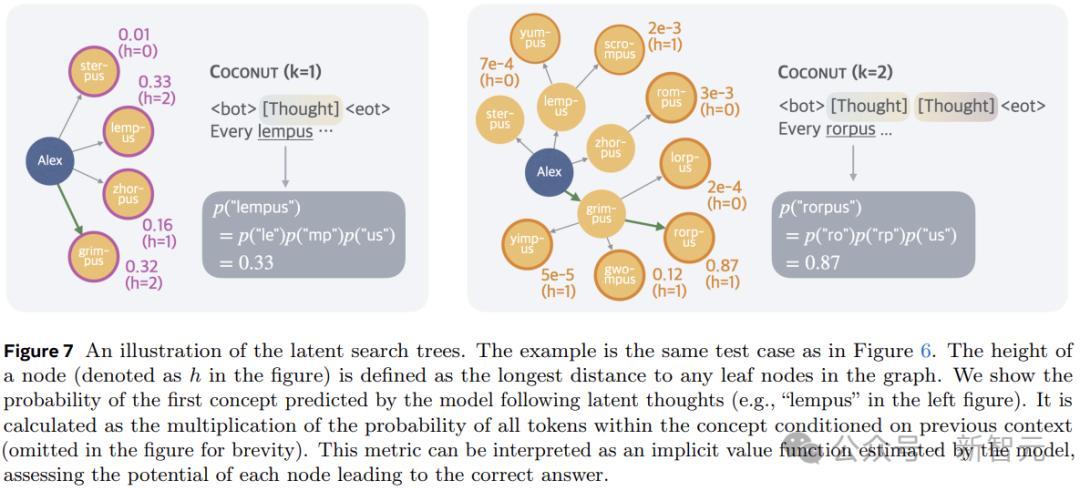
为了科罚这个问题,本文应用了新的数据集构建管谈,使用随即生成的DAG来构建已知条款。生成的数据集要求模子对图进行多数推敲和搜索,以找到正确的推理链。这个新数据集被称为ProsQA,如下图所示。
实验研讨以下基线:
1)CoT:使用完好的推理链来历练谈话模子,并进行监督微调,推理经过中,模子先生成推理经过再输出回应。
2)No-CoT:LLM径直生成谜底。
3)iCoT:使用谈话推理链进行历练,并将CoT 「内化」。历练经过中,推理链着手的token会缓缓被移除,终末只剩下谜底。推理经过中,模子径直估计谜底。
4)Pause token:模子仅使用问答进行历练,莫得推理链。但在问题和谜底之间插入了特殊token,为模子提供了特别的策划才调来得出谜底。
实验还评估了本文活动的一些变体:
1)w/o curriculum:径直使用终末阶段的数据,不进行多阶段历练。
2)w/o thought:使用多阶段的历练,缓缓去除谈话推理活动,但不使用任何结合的潜在想维。这在见识上与iCoT相通,但践诺的历练经过与Coconut保合手一致。
3)Pause as thought:使用特殊的 token来代替结合的想考,并应用与Coconut交流的多阶段历练。
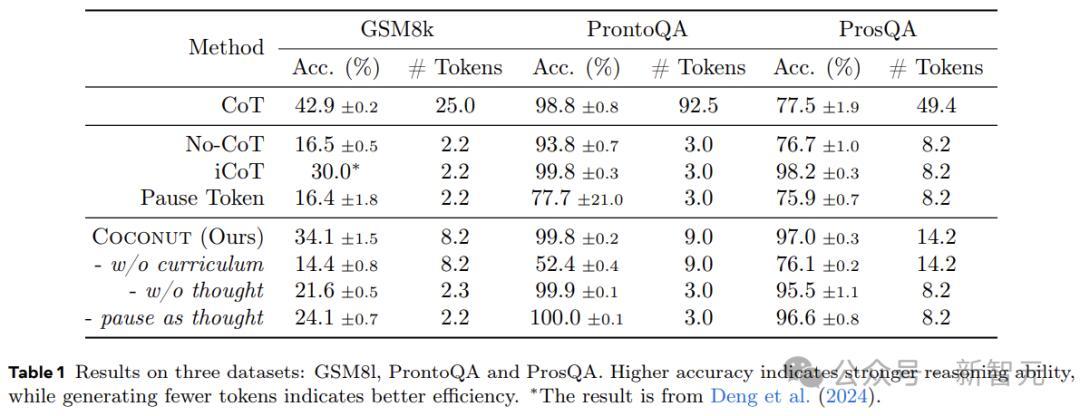
表1披露了所独特据集的总体闭幕。Coconut的效用很高,而况在ProntoQA和ProsQA上披袒露比CoT更好的性能。
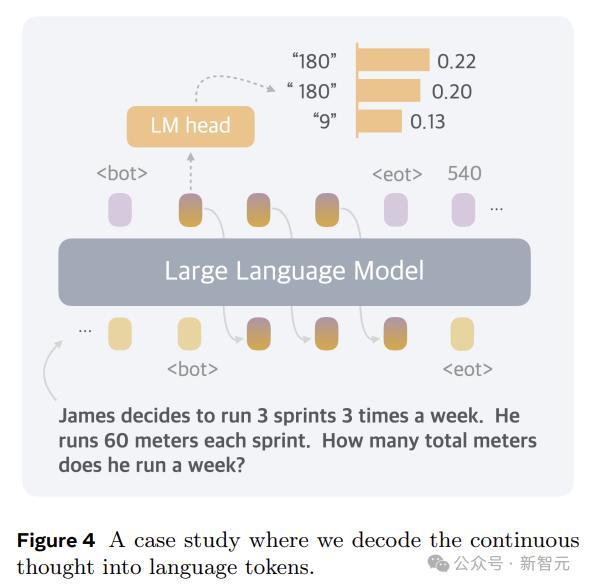
上图展示了Coconut将不同陈迹的踱步编码到结合的想想中,为推敲密集型推理任务启用了更高等的推理形式。
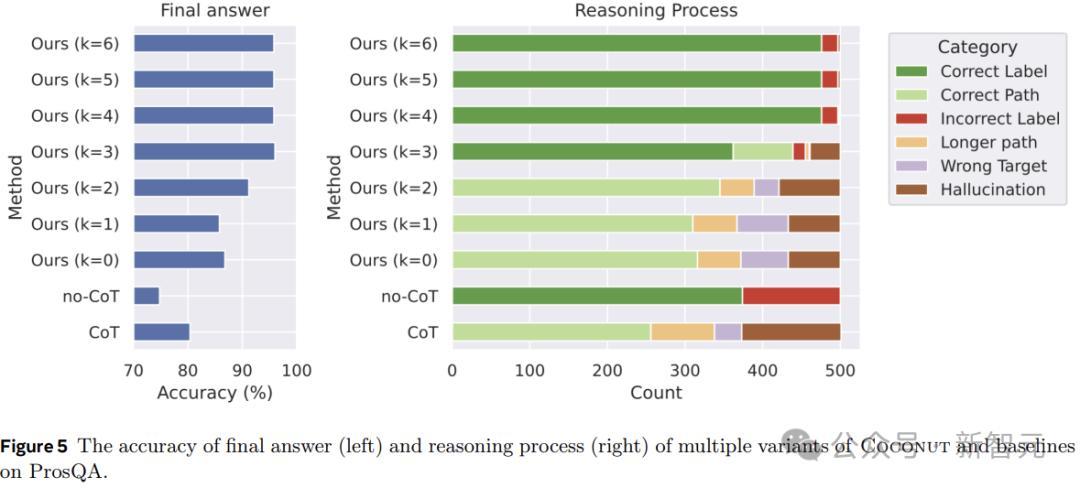
图5披露了ProsQA上不同推理活动的比较分析。跟着更多地通过结合想考(加多k)进行推理,最终谜底的准确性(左)和正确推理经过的速度(右)都会提升。
此外,「幻觉」和「造作策划」的发生率会裁汰,这也讲明当潜在空间发生更多推理时,推敲才调会更好。
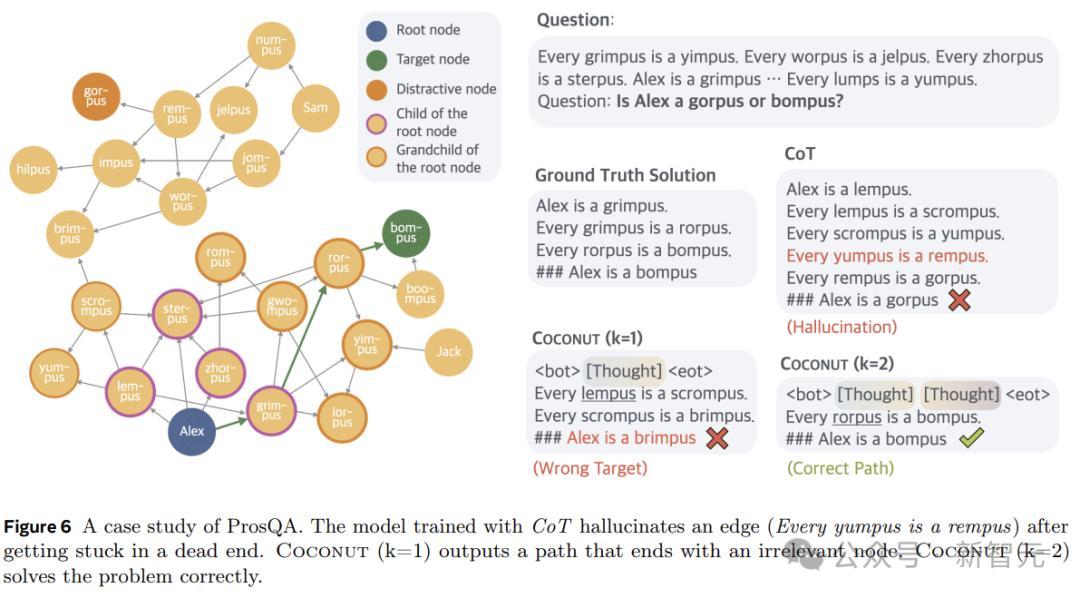
图6披露了一个案例盘问,其中CoT产生幻觉(一个不存在的边)导致了造作的策划,但Coconut(k=2)奏效科罚了这个问题。潜在推理可以幸免事前作念出劳苦的遴荐,模子可以在后续活动中冉冉排斥不正确的选项,并在推理竣事时得回更高的准确性。
参考尊府:
https://arxiv.org/abs/2412.06769
https://x.com/tydsh/status/1866577470591471788
Powered by 天臣配资 @2013-2022 RSS地图 HTML地图
建站@kebiseo; 2013-2024 万生优配app下载官网 版权所有